
In Part 1 of this post, I pointed out the key difference between two different types of Oracle chained rows — chained rows that were actually migrated rows (which have a negligible impact on Exadata offloading), and truly chained rows that will not fit in one 8K block (and surprisingly had less of an impact than I thought).
All of the previous testing was done with ROW STORE COMPRESS ADVANCED (Advanced Compression), and the question was asked — does storing the table in Exadata at some HCC compression level help avoid truly chained rows? Ideally you won’t need to get in that situation by using CLOBs or a different design method, but until then, Exadata to the rescue!!! Again.
I did this testing with a similar test table; I created a table that has chained rows in an uncompressed version and then tested five other compression methods on the same table (ROW STORE COMPRESS ADVANCED, COLUMN STORE FOR [QUERY LOW | QUERY HIGH | ARCHIVE LOW | ARCHIVE HIGH]:
create table compr_rows
(
id number not null,
note_text1 varchar2(4000),
note_text2 varchar2(4000),
note_text3 varchar2(4000),
ins_dt date not null
) nocompress nologging;With an 8K block size and three 4K VARCHAR2 columns populated with random characters, there are going to be chained rows. I populated 50,000 rows this way, with varying VARCHAR2 sizes from 2,501 to 3,250 bytes, ensuring that Oracle Exadata features would kick in with a large enough segment size:
insert /*+ append parallel(8) enable_parallel_dml */ into compr_rows
(id,note_text1,note_text2,note_text3,ins_dt)
select trunc(dbms_random.value(1,100)),
substr(dbms_random.string('a',3500),1,2500+dbms_random.value(1,750)),
substr(dbms_random.string('a',3500),1,2500+dbms_random.value(1,750)),
substr(dbms_random.string('a',3500),1,2500+dbms_random.value(1,750)),
sysdate-dbms_random.value(1,100)
from dual
connect by level <= 50000;I recreated the table five more times at the five compression levels and checked both the segment size and number of chained rows. The results are summarized in the chart below.
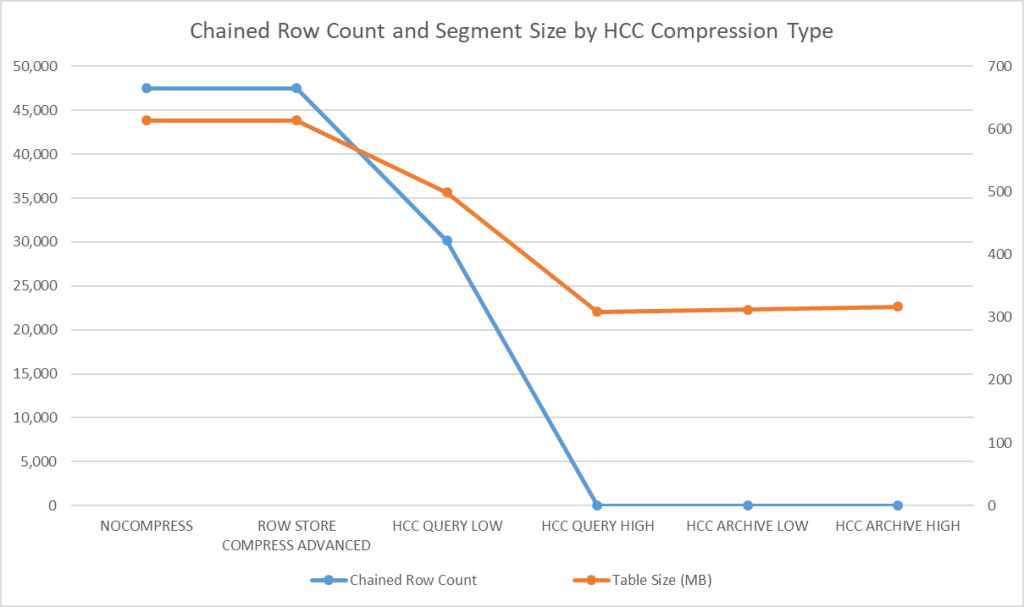
Takeaways
- Advanced Compression doesn’t do much with random data! That makes sense since Advanced Compression tokenizes common values for a column, and no two columns in a block are likely to be identical.
- Using HCC QUERY LOW does compress a bit better than ROW STORE COMPRESS ADVANCED and reduces chained rows significantly.
- Once you get to HCC QUERY HIGH, all of the chained rows disappear and the maximum compression level kicks in — reducing the size by more than half — remember, this is on random strings of characters!
- Using either HCC ARCHIVE LOW or HCC ARCHIVE HIGH takes more CPU and actually makes the segment a bit larger.
The three compression algorithms used by Exadata HCC include LZO, ZLIB, and BZ2; It’s a trade-off between table size and CPU usage. Using HCC QUERY HIGH ends up being a good compression level for many reasons — high compression, reasonable CPU usage, and often the higher CPU usage is offset by savings in I/O waits and offloading operations! If you happen to end up with a lot of chained rows, then HCC QUERY HIGH is another good reason to consider it for your big tables that have infrequent or no DML activity.
