
In a previous blog post, I showed how using flash storage on Exadata can extend the Oracle in-memory capacity by using flash storage in conjunction with the INMEMORY_FORCE parameter, even without using DRAM in the compute layer.
The nagging question in the back of my mind remained: “Sure, I might have 100 TB of in-memory capacity in flash compared to only 1.5 TB in DRAM per server, but is it going to be anywhere near as fast as using DRAM?” I only had to run a few tests to come up with the initial answers.
Environment
The environment setup was the same as before — using the Sample Star Schema Benchmark tables and sample data available for any Oracle database via Andy Rivenes’ GitHub.
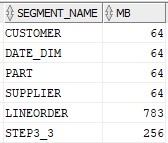
The populated tables aren’t very large from an Exadata perspective but big enough to compare the in-memory performance between the compute layer and the storage layer. All of the tables were marked with this in-memory attribute:
INMEMORY PRIORITY HIGH MEMCOMPRESS FOR QUERY LOW Benchmark Query
I used only one query to test the in-memory performance with the two different parameter settings. It would be guaranteed to perform a full table scan on all tables with the GROUP BY and no WHERE clause:
select /*+ monitor */
c_custkey, c_nation, count(lo_orderdate)
from customer c
join lineorder l
on c.c_custkey = l.lo_custkey
group by c_custkey, c_nation;The query returns 900 rows and the first few rows look like this:

Metric Comparison
To compare the performance of the two environments, I used these parameters to leverage in-memory at the compute layer:
INMEMORY_SIZE=256G
INMEMORY_FORCE=DEFAULTand these parameters to leverage only the in-memory column store in flash:
INMEMORY_SIZE=0
INMEMORY_FORCE=CELLMEMORY_LEVELTesting Results
I used both SQL Monitoring reports and metrics from V$MYSTAT to see where all the activity occurred. From an elapsed time perspective:

The run times were almost the same, which was pleasantly surprising — but that also meant that I will need to do more scalability testing in the future. From the I/O perspective, I got some surprising results:

I didn’t expect any I/O from in-memory at the compute level, since all the tables were populated in memory; however, even though a 90% offload efficiency is really good, there was some I/O. Which made sense since the tables are cached in flash at the storage level, albeit they were stored in the same in-memory format as if they were in DRAM. How is that I/O broken down? To find that out, I had to compare the metrics counters in V$MYSTAT, which made things a lot clearer.

That’s likely not very readable, even on a big monitor, but the takeaway is clear — the events at the compute layer are what you’d see on Oracle non-Exadata hardware for in-memory operations:

In contrast, you’ll instead see these statistics at the storage level in flash, and clearly processing the HCC-compressed CUs in flash in an in-memory format:
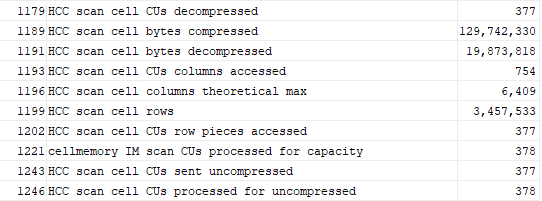
One more thing I noticed — PMEM cache read hits were higher for in-memory at the storage level. That looks like something else I’ll be investigating soon, since PMEM is another tier of storage in X8M and X9M that can really reduce the latency between the compute layer and the storage layer.

Summary
In absolute terms, having a large enough DRAM-based in-memory column store on each database server and the CPU resources to manage it is going to be the most performant solution. But with high CPU usage at the compute layer and petabyte databases whose key table columns won’t fit in memory even across multiple RAC nodes on Exadata, using the in-memory column store at the storage layer can still give you the performance you need well beyond traditional database architectures.

One comment