
The title of this article does not have a typo. ARCHIVELOG mode has been a foundational element of Oracle Database for every version I can remember. As the online redo log files switch, the previous log file is written to one or more archive log destinations. This is required for precise database recoverability up to any point in time or System Change Number (SCN). But how many of these archived log files do you really need?
In most cases, all of them! But in this particular scenario, a customer had to create and populate a set of “temporary” tables containing over 2 TB of rows, then truncate or drop them later in the day. Usually, a Global Temporary Table (GTT) would be ideal for this reason since it uses the TEMP tablespace, and with TEMP_UNDO_ENABLED=TRUE, almost no redo is generated. However, the rows in these “temporary” tables needed to be shared across sessions, which eliminated GTTs as an option.
When using ARCHIVELOG mode, the NOLOGGING attribute at the table level, and APPEND (direct path writes), the amount of redo generated is low; the DAILY_TRANSACTIONS table is about 5 GB. I’ll make a full copy of DAILY_TRANSACTIONS that multiple sessions may revise and query later as a “temporary” table:
create table temp_daily_transactions
nologging as
select * from daily_transactions where 1=0;
insert /*+ append enable_parallel_dml parallel(4) */
into temp_daily_transactions
select * from daily_transactions;
commit;
select s.name, m.value
from v$statname s
join v$mystat m
using(statistic#)
where lower(s.name) = 'redo size';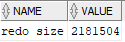
That’s only a bit over 2 MB, primarily for metadata related to the CREATE TABLE statement. But if you do that 1 million times a day, that’s at least 2 TB of redo that will end up as archived redo in the archive destination(s) as well as in one or more Oracle Data Guard destinations.
Alternative Redo-Free Options
Combining tables with the NOLOGGING attribute and using direct path methods to populate the table gets us far, but can we get closer to zero?
To see if I can reduce redo generation even further, I found a way to using an Oracle Database external table type that has many uses: the Data Pump driver. The big advantage to the Data Pump driver for external tables is that you can write to an external Data Pump table in addition to reading it. To create an external table with that driver, create the Oracle directory if it already doesn’t exist, then create the table with the TYPE ORACLE_DATAPUMP clause:
create directory dp_ext as '/orabackup/dpump/ext';
create table daily_transactions_ext
organization external
(
type oracle_datapump
default directory dp_ext
location('daily_transactions.dmp')
)
as
select * from daily_transactions;How much redo was generated? Almost none:
select s.name, m.value
from v$statname s
join v$mystat m
using(statistic#)
where lower(s.name) = 'redo size';
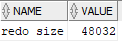
Accessing the table DAILY_TRANSACTIONS_EXT is fast when you need to scan the entire table; as with any external table, you can’t define any indexes on it, though you can have a hybrid external table where some of the partitions are on traditional Oracle storage and some in an external table. The scan performance will depend on how fast the external storage is. Since it’s a temporary table from my application’s perspective, the external storage’s redundancy and high availability is not as big of a concern.
But Wait, There’s More!
External tables can play an even larger role in your Exadata environment with two relatively new features: in-memory support for external tables and extending in-memory functionality to Exadata storage servers. Stay tuned for new posts that explore extending Exadata storage with external tables.
