
I’m not talking about Internet Of Things devices, but of course Oracle Index Organized Tables, which have been available in Oracle Database long before Exadata existed. The advantage of IOTs has always been combining the data and index for a table into a single segment (with an optional overflow segment, which I’ll talk more about later).
With at least the mandatory primary key index, retrieving a single row from an IOT will always take fewer I/Os since once you’ve found the desired row with the PK index, the column data for that row is usually going to be in that leaf block.
Sample Dataset
To do the analysis of IOTs on Exadata, I used a subset pf the LINEORDER table from the SSB (Star Schema Benchmark) which is included with any Oracle Cloud Autonomous Database so it was convenient for doing comparisons between environments. Total number of rows in LINEORDER is 90,405,201.
I created 5 “versions” of the LINEORDER table:
- NOCOMPRESS_LINEORDER: a heap-based version with both the table and index uncompressed
- COMPR_ADV_LINEORDER: a heap-based version using Advanced Compression with a primary key index that is compressed with COMPRESS ADVANCED HIGH
- IOT_LINEORDER: an IOT that does not have an overflow segment
- IOT_OVER_LINEORDER: an IOT version which includes an overflow segment that contains the columns after the first two non-primary key columns
- QUERY_HIGH_LINEORDER: an HCC QUERY HIGH version without an index
The heap-based version, available on any Oracle platform, was compressed with Advanced Compression on the table segment and COMPRESS ADVANCED HIGH for the index. For indexes that are updated often, COMPRESS ADVANCED LOW may be more suitable, but the goal was to minimize segment size.
The IOT version with the overflow segment was created with this DDL:
CREATE TABLE "IOT_OVER_LINEORDER"
("LO_ORDERKEY" NUMBER,
"LO_LINENUMBER" NUMBER,
"LO_CUSTKEY" NUMBER,
"LO_PARTKEY" NUMBER,
"LO_SUPPKEY" NUMBER,
"LO_ORDERDATE" DATE,
"LO_ORDERPRIORITY" CHAR(15 BYTE) COLLATE "USING_NLS_COMP",
"LO_SHIPPRIORITY" CHAR(1 BYTE) COLLATE "USING_NLS_COMP",
"LO_QUANTITY" NUMBER,
"LO_EXTENDEDPRICE" NUMBER,
"LO_ORDTOTALPRICE" NUMBER,
"LO_DISCOUNT" NUMBER,
"LO_REVENUE" NUMBER,
"LO_SUPPLYCOST" NUMBER,
"LO_TAX" NUMBER,
"LO_COMMITDATE" NUMBER,
"LO_SHIPMODE" CHAR(10 BYTE) COLLATE "USING_NLS_COMP",
constraint pk_iot_over_lineorder
primary key (lo_orderkey,lo_linenumber,lo_custkey,lo_partkey,lo_suppkey,lo_orderdate)
)
organization index
including lo_shippriority
overflow;
Lines 2-7 are the primary key of the IOT; the including clause in line 23 indicates that the LO_ORDERPRIORITY and LO_SHIPPRIORITY columns are stored in the index segment. The remaining columns reside in the overflow segment.
The resulting sizes of the tables and indexes is interesting but not surprising:

The uncompressed heap-based version of the table plus index is about 16 GB. The PK index is somewhat large in relation to the table size since it has six columns. For the heap-based Advance Compression version of the table, the size of the table is reduced by about 20% and the index about 30%.
Index-organized tables cannot be compressed*. But since the data in an IOT is stored as part of the index itself, some space savings are realized and its size is about the same as the uncompressed version of the table itself regardless of whether there is an overflow segment.
On Exadata, using HCC Query High, the table segment shrinks to about 1/3rd of the uncompressed size. Presumably the high level of compression and no index would be suitable for the table if it were in an analytical environment instead of an OLTP environment.
What About Prefix Compression?
Notice the asterisk in the previous section! IOTs do support the original COMPRESS X option, known as prefix compression. One or more components of a multi-column key can be logically compressed by removing duplicate values of index entries in a block when the index values after index column X repeat.
In this scenario, I left out the test case with prefix compression because the index segment actually increased in size instead of decreasing:

This is the downside of prefix compression — there is overhead in each block to maintain the metadata for de-duplication of index entries. When there are few or no duplicates in an index prefix, the index segment gets larger instead of smaller!
That’s one of the advantages of the newer index compression options COMPRESS ADVANCED LOW and COMPRESS ADVANCED HIGH: an index block is compressed only if the size of the block is reduced with compression.
Query Performance
To test how a query against a non-indexed column performs for each table type, I used a query filtering on the LO_REVENUE column:
select /*+ parallel(4) */ *
from <table_type>_lineorder
where lo_revenue=4065930;<table_type> is one of NOCOMPRESS, COMPR_ADV, IOT_LINEORDER, IOT_OVER_LINEORDER, QUERY_HIGH_LINEORDER. This query returns 22 rows out of 90,405,201.
To Offload or Not Offload, Is That the Question?
The uncompressed and compress advanced heap versions of the table performed as expected. Since there is no index on the LO_REVENUE column, a full table scan occurs at the storage level:
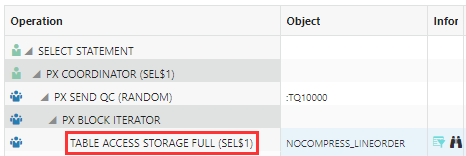
In addition, when the table is scanned at the storage layer, the reads are all direct path 1K reads, with only a fraction of the table’s rows returned to the database layer:

The two IOT versions of the table performed poorly, especially when the filtering column resides in the overflow segment. A fast full scan of the PK index means that every block of the non-overflow portion of the IOT is scanned, then each block of the overflow segment:
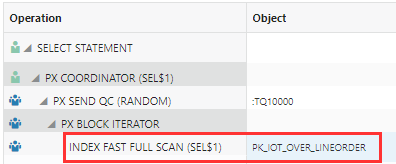
What else is sub-optimal with this IOT version? All of the reads are single block reads, there is no offloading, execution time almost 10 minutes, and the total I/O is 3x the size of the combined index and overflow segment!


As expected, the QUERY_HIGH version of the table performed the best — lowest I/O, 100% offloading, and shortest execution time:

Conclusions
Index-organized tables can still be useful in OLTP systems but have some limitations on engineered systems like Exadata. As of Oracle Database 19c, IOTs cannot be offloaded to storage with operations such as TABLE STORAGE ACCESS FULL. Even though they are fundamentally tables structured as indexes, you will also not see operations in the execution plan such as INDEX STORAGE ACCESS FULL that are available for heap-based table indexes.
It will be interesting to see some of the rumored enhancements in Oracle Database 23c related to compression options for IOTs, as well as how IOTs can be leveraged more effectively on an Exadata platform. Those answers and more will be answered in Part 2!

One comment