
Exadata features save the day for me more often than not, but it’s also the built-in features of Oracle Database that come to the rescue when I least expect it. A combination of an inline PL/SQL function and Exadata offloading helped me fix an issue with DATE columns whose values were not valid for the time zone when the date value was recorded.
Invalid DateTime Value in the Current Time Zone
In a few of my tables, there are columns defined as DATE that were inserted without any accompanying time zone attribute. In retrospect, the column would have been more accurate as a TIMESTAMP WITH TIME ZONE column, but the process for changing the data type of these columns won’t happen any time soon. Because Daylight Savings Time (DST) starts in the U.S. every March or April on a Sunday, the time of day moves an hour ahead and there is a gap from 2:00 A.M. to 3:00 A.M. For some yet undetermined reason, some of the DATE columns are recorded on this day between those hours, and we don’t find out about those rows until a conversion to a TIMESTAMP WITH TIME ZONE column is attempted with the relevant time zone. This SELECT statement shows what happens when I try to convert a non-existent DATE value (between 2:00 A.M. and 3:00 A.M.) to a TIMESTAMP WITH TIME ZONE data type.
select FROM_TZ(CAST(date'2022-03-13'+2.1/24 AS TIMESTAMP),'America/New_York')
from dual;On March 13th, 2022, the time moved an hour ahead, so 2:00 A.M. became 3:00 A.M. in New York (and in most every other time zone in the United States). The offset from midnight of “2.1/24” is 2:06 A.M., which does not exist on 3/13/2022, so I get an ORA-01878 error:

If there are only a few rows in a small table with this problem, they are easy to find. But I had a table with over 100 million rows, and I had to identify the bad rows as a first step.
In-Line Functions
A standard SELECT statement would give me the ORA-01878 error, but wouldn’t tell me which row or rows had the issue. I could write an anonymous PL/SQL procedure to find the problematic dates, but that would increase the complexity of the solution. As a hybrid approach, I decided to write a SELECT statement that included an in-line function — much like a CTE, but for PL/SQL functions that would only exist for the duration of the SELECT statement:
with
function check_tz(in_dt in date) return timestamp with time zone is
tz_nonexistent_date exception;
pragma exception_init (tz_nonexistent_date,-1878);
begin
return from_tz(cast(in_dt as timestamp),'America/New_York');
exception
when tz_nonexistent_date then return null;
end;
select /*+ parallel(8) monitor */ cust_id, subscr_begin_dt
from cust_subscription
where subscr_begin_dt is not null
and extract(month from to_timestamp(subscr_begin_dt,'YYYY-MM-DD HH24:MI:SS')) in (3,4) -- March or April
and extract(hour from to_timestamp(subscr_begin_dt,'YYYY-MM-DD HH24:MI:SS')) = 2 -- from 2 A.M. to 2:59:59 A.M.
and check_tz(subscr_begin_dt) is null
order by subscr_begin_dt;
Because the function call is “in-line”, the context switching between SQL and PL/SQL is minimal, but that would add up for 100 million rows so I added two more key filters to the WHERE clause: the MONTH would have to be March or April, and the HOUR would have to be 2 (2:00 A.M. to 3:00 A.M.). I know it’s a “bad” date when the exception handler for ORA-01878 (and that error only!) returns a NULL value instead of the TIMESTAMP WITH TIME ZONE value for that DATE.
Exadata Offloading to the Rescue!
The run time was even faster than I expected, so I looked at the SQL Monitoring report to see why:
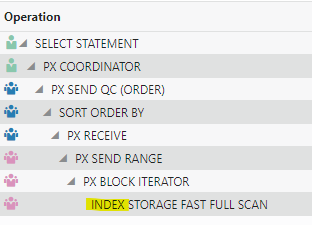
One or more of the predicates in my query along with a full table scan enabled offloading at the storage level. As a bonus, it was able to do the scan at the storage level with an index! Yes, a full index scan reminded me that indexes are still a thing on Exadata. Looking at some of the other execution statistics, I was able to offload 97% of the I/O to the storage level:

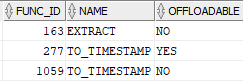
Most of the table data I needed was already in flash, and from that, only about 3% of it had to be returned to the compute (DB) layer. Looking at V$SQLFN_METADATA, I can see that the EXTRACT function (and perhaps TO_TIMESTAMP) can be offloaded to storage.
Next Steps
It’s not clear why TO_TIMESTAMP is listed twice in V$SQLFN_METADATA, but now I have an easy and fast way to identify DATETIME values that technically don’t exist in a particular time zone. The recent initiatives to eliminate time changes and making DST permanent means I will hit these errors less likely. Until then, Exadata features will continue to make my job easier (not to mention helping me win friends and influence people).
