
Chained rows in a table are generally a “bad thing”, but how bad depends on the type of chained row. Oracle Database contributes to the confusion about chained rows since there are two types of chained rows: rows that won’t fit in a database block and rows that became too big for a block and were moved to another block — also known as migrated rows. The way Oracle Database identifies chained rows adds to the confusion and lumps them into one category.
Ideally you won’t have either type of chained row in your database but it’s sometimes unavoidable when you have one or more VARCHAR2 columns that keep getting bigger until it just won’t fit into its current block and you’ve exhausted the free space in the block over time (PCTFREE).
As usual, there’s an Exadata angle to chained rows. I ran some tests with both types of chained rows on Exadata with one of the more recent versions of Exadata software (version 19.2.4.x) from an Oracle 12.2.0.1 database. The first set of results was expected, and the second set of results was not — I was pleasantly surprised by what the cell server offload engine could do even under the worst scenario.
Table Used for Testing
To exhibit the issues with the two types of chained rows, here’s the table I created that will be populated and then updated later.
create table widerows
(
id number not null,
note_text1 varchar2(4000),
note_text2 varchar2(4000),
ins_dt date not null
) row store compress advanced nologging;
The first chained row demonstration (migrated rows) will only use NOTE_TEXT1; NOTE_TEXT2 will stay empty. For the second chained row demonstration (true chained rows), both NOTE_TEXT1 and NOTE_TEXT2 will be populated with 4000 bytes to demonstrate the second type of chained row. For both tests the target segment size will be approximately 1 GB which is big enough on this Exadata box to trigger offloading (or not!).
Chained Rows Part 1: Not So Much
For the first test, I populated WIDEROWS with 1M rows, populating ID and INS_DT with somewhat random values and NOTE_TEXT1 with 400 random characters in each row:
insert /*+ append parallel(8) enable_parallel_dml */
into widerows (id,note_text1,note_text2,ins_dt)
select trunc(dbms_random.value(1,100)),
dbms_random.string('a',400),
null,
sysdate-dbms_random.value(1,100)
from dual
connect by level <= 1000000;
commit;
After inserting 1M rows, the average row length was 412, which sounds right for NOTE_TEXT1 being 400 bytes in each row plus ID and INS_DT occupying 12 bytes in each row.
Pre-UPDATE Offloading Behavior
Testing how well the cell server offloading engine works, I run a query that should exercise both the selection and projection features of Exadata:
select /*+ monitor parallel(4) */
id,ins_dt,substr(note_text1,1,10) partnote
from widerows
where id in (12,58);
The query returns about 20K rows (out of 1M). The cell statistics confirm that only the desired rows were returned to the compute layer:

The approximately 20K rows * 412 bytes per row ~= 8MB which lines up with what was returned to the client application. The entire segment is about 482 MB, so that’s a big savings in I/O that either happens at the storage layer or at a minimum doesn’t have to be returned to the client.
Column projection is also happening at the storage layer: if instead the query only returned ID and INS_DT:
select /*+ monitor parallel(4) */
id,ins_dt
from widerows
where id in (12,58);
the number of bytes returned to the client is even lower:

If you don’t need to see NOTE_TEXT1 in your query results, that’s another 85% reduction in the bytes returned to the compute layer.
Post-UPDATE Offloading Behavior
By default, the WIDEROWS table has PCTFREE=10, meaning that 10% of each block is reserved for column expansion: some columns that originally had NULL values may later be populated; VARCHAR2 columns may be widened. What happens to offloading if I double the number of bytes in the NOTE_TEXT1 column, which currently is 400 bytes in each row?
update /*+ enable_parallel_dml parallel(8)*/ widerows
set note_text1=note_text1 || dbms_random.string('a',400);
commit;
With about 20 rows per block in the WIDEROWS table, some of the rows will no longer fit in their original block, and therefore the entire row is migrated to a new block, with only the pointer to the new block left behind in the original block. Oracle Database considers these rows to be chained rows:
select table_name,count(*) migrated_rows
from chained_rows
where table_name like '%WIDEROWS%'
group by table_name;
TABLE_NAME MIGRATED_ROWS
----------------- -------------
WIDEROWS 470584
Out of 1M rows, almost half of them have been migrated to a new block. How do migrated rows affect offloading? Running this query again:
select /*+ monitor parallel(4) */
id,ins_dt,substr(note_text1,1,20) partnote
from widerows
where id in (12,58);
I find that the answer is “not at all”:

Because the size of the table’s VARCHAR2 column has doubled, the size of the segment is about double and the number of bytes returned to the compute layer has doubled as you might expect. The SQL Monitoring report shows the good news in a more readable format:
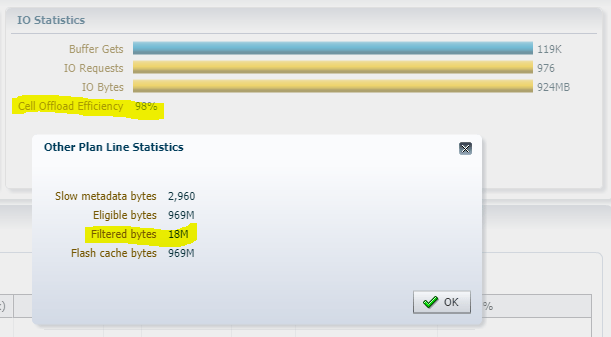
Out of the 924MB allocated to the segment, the offloaded selection and projection operations only had to return 18MB. As a bonus, the bytes that did have to be returned were in the flash cache already.
When a row is migrated to a new block, the entire contents of the row reside in a new block with only a ROWID pointer in the original block. When a full table scan occurs, which is what happens in the Exadata storage layer when TABLE STORAGE ACCESS FULL is used for a query plan step, there’s no need to “follow” the old ROWID pointer in the old block to the new block since every block is going to be read during a full table scan operation.
If the table is often the target of an index range scan, there will be an additional I/O to retrieve the second block to get the actual row contents. However, if that becomes a serious performance bottleneck, it can be alleviated by an occasional ALTER TABLE MOVE to rebuild the table into a new segment without the extra ROWID pointers.
Chained Rows Part 2: Very Chained
What about truly chained rows? In other words, a given row will not fit into a single block? In this second scenario I insert 65K rows into the table and ensure that every row will not fit into a single block with an 8K block size:
insert /*+ append parallel(8) enable_parallel_dml */ into widerows
(id,note_text1,note_text2,ins_dt)
select trunc(dbms_random.value(1,100)),
dbms_random.string('a',4000),
dbms_random.string('a',4000),
sysdate-dbms_random.value(1,100)
from dual
connect by level <= 65000;
commit;
Because there are two VARCHAR2s that will always have 4000 bytes each in addition to the other columns in the table, every row in the table has its contents split across two blocks and as a result every row is chained:
TABLE_NAME CHAINED_ROWS
----------------- -------------
WIDEROWS 65000
After running the first query, returning ID, INS_DT, and NOTE_TEXT1:
select /*+ monitor parallel(4) */
id,ins_dt,substr(note_text1,1,20) partnote
from widerows
where id in (12,58);
The cell statistics reveal the awful truth that the WHERE clause now has to be evaluated at the compute layer; all offload processing is skipped and the entire contents of each row is being returned:

That’s 65K rows in the table * average row size of 8013 = 521M. However, you may have immediately noticed one bright side to this scenario:

The segment size of WIDEROWS is 1GB, however, only 483MB was returned to the compute layer — with two VARCHAR2(4000) columns in each row fully populated, each row must reside in its own block — leaving about half of each block empty! Even with no selection or projection happening at the storage layer, rows from the table are not returned as full 8K blocks that are half-empty but in a much more compact format thanks to the iDB protocol (Intelligent Database protocol).
Exadata is Getting Smarter with Every Release!
Chained rows due to row migration have a negligible effect on Exadata performance when storage offloading happens: you still get the projection and selection features that dramatically reduce the amount of data sent back to the compute layer.
Chained rows due to row contents residing in more than one block — resulting in some of Exadata’s functionality not being used — result in all rows being returned to the compute layer for predicate evaluation and column projection. However, thanks to the iDB protocol, the cell servers will still return only the contents of the columns and not the blocks themselves.
Your logical database design, ETL process flow, and physical database implementation still need to happen up front to avoid chained rows of any kind, but when Exadata is part of the physical implementation, it will still avoid performance issues that might have occurred with storage on traditional Oracle Database platforms.

One comment