
In most of the environments I work in, ETL is a necessary evil: extract the information from one or more OLTP tables and insert it into tables more suitable for business intelligence processing. The catch is that partitioning strategies are typically different in an OLTP database compared to a BI or DSS database with fact and dimension tables.
Scenario
The STG table is not partitioned by default. For the ORDER_ID column the order IDs are almost all new or recently revised orders from the web site. The RPT table is range partitioned by ORDER_DATE. A typical ETL query uses a LEFT OUTER JOIN between the STG table and the RPT table:
select systimestamp, s.order_id, s.rev_item_count, r.order_date
from
stg s
left outer join rpt r
on s.order_id = r.order_id;No Changes to Partitioning
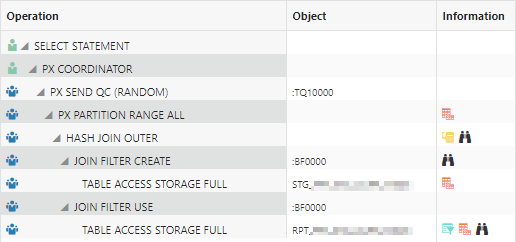
When the STG table is outer joined to the RPT table with that query using parallel query and offloaded bloom filters the plan looks reasonable:

The I/O was too high, approaching the size of the table:

“What If” RPT were SUBpartitioned by ORDER_ID?
To minimize the disruption to ongoing operations and table structure, the RPT table was subpartitioned by ORDER_ID and the STG table was partitioned by ORDER_ID. As it turns out, the Oracle optimizer does not appear to implement partition-wise joins between the partitions of the first table and subpartitions of a second table efficiently, even if the partition key and partition width are the same. The plan has a “PART JOIN FILTER CREATE” and runs a little faster but does the same amount of I/O.

Partitioning RPT on ORDER_ID
To see if partition pruning will work better with “same level” partition-wise joins, I changed the RPT table to partition on ORDER_ID and subpartitioned on ORDER_DATE so that existing queries expecting the RPT table to be partitioned on ORDER_DATE would still partition prune with almost exactly the same performance. As a result, I got the same execution plan as before, but I cut the I/O down by more than half! Still, no offloading.

But Wait, Is There More?
One of the things I try in a later optimization stage is to investigate how much or if a table should be compressed with HCC. Rebuilding the RPT table as HCC QUERY LOW produced some impressive yet slightly unexpected results — bloom filters at the storage level were still utilized, but the bloom filters were not built per partition since the PART JOIN FILTER CREATE step is not in this plan:
The offloading percentage can sometimes be misleading, since you can’t actually offload more than 100% of the I/O. But running in 2 seconds with doing only 2.5 GB of I/O is definitely a win in this scenario.

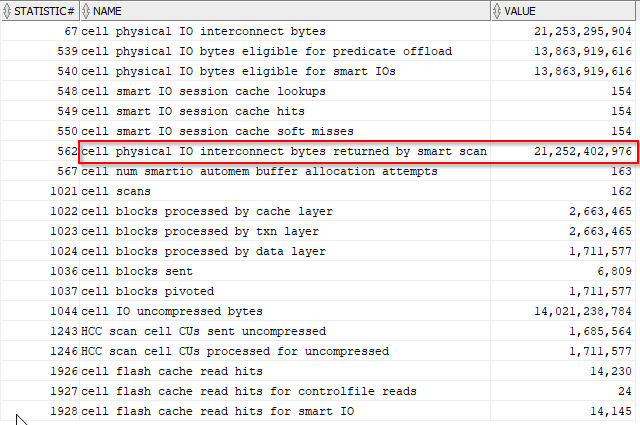
That’s why it’s good to look at the session statistics in V$MYSTAT to see the actual numbers:

About 43x more bytes were returned by the first query with no partitioning and a bloom filter:
The RPT table with Advanced Compression was 14.6 GB; with QUERY LOW it is 6.2 GB.
Conclusions
Keep in mind that you can typically take advantage of several Oracle features simultaneously — whether they appeared in Oracle Database version 9i or Exadata version 22.1 on an Exadata X9M.
In this case, Exadata offloading, bloom filters, compression, partition pruning, and implementing subpartitioning combined to cut down the actual I/O by more than 80% and execution time by up to 90%. Not all of those features need to be used at once depending on the data set sizes, the selectivity of the join conditions, and the tolerance for CPU overhead to maintain higher levels of Exadata compression.
