

Is Swiss Cheese That Bad for your Database?
HCC (Hybrid Columnar Compression) has been a feature of Oracle Exadata since the beginning; its four variations (query low, query high, archive low, archive high) have different levels of compression with corresponding overhead for compress and decompress, even if the decompression is happening at the storage layer. The biggest caveat has always been — “avoid DML on existing HCC-compressed segments due to locking issues at the compression unit (CU) level and the potential to change the block or CU compression to Advanced Compression during those DML operations.” Plus, of course, the extra CPU overhead to perform the compression operations.
One of the applications I work with has two distinct workloads: ETL and reporting, much like most database applications. The important distinction to the ETL workload is that there is no OLTP activity — row by row — just bulk DELETEs followed by bulk INSERTs for every reporting table. Since Oracle Database version 12.2, any bulk INSERTs will happen in direct path mode, even without the APPEND hint.
Test Setup
To find out the best possible table compression level for these workloads, I captured the extract files over 11 days and monitored the execution time and segment size for each of 6 compression levels: NOCOMPRESS, COMPRESS ADVANCED, QUERY LOW, QUERY HIGH, ARCHIVE LOW, and ARCHIVE HIGH. The execution time is essentially equivalent to DB Time: a combination of I/O and CPU waits. I ran the tests with an explicit NOAPPEND for the INSERT statement; it won’t reduce the size of the HCC table since it should* always use APPEND.

The size of the QUERY LOW version of the table may eventually “catch up” to the COMPRESS ADVANCED version, but it will be less than half the size. But what about the elapsed time — will ETL spend a lot more time compressing the rows with HCC, or spend more time reading the rows during the report phase or even during successive ETL jobs? The answer was not too surprising:
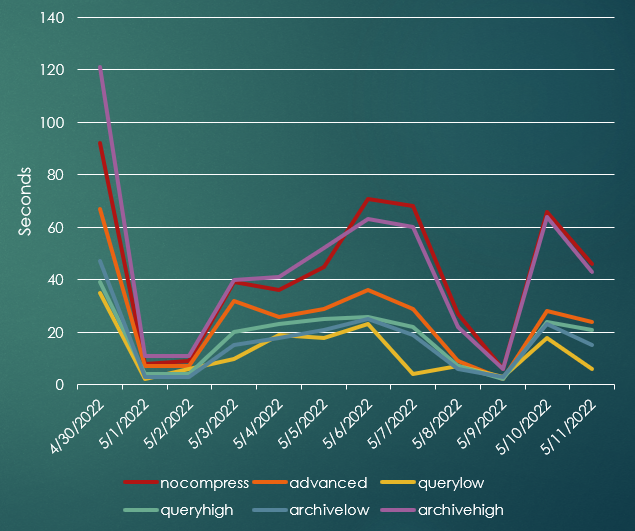
Even with DELETEs that might leave behind some “holes” in the table CUs, using QUERY LOW was almost always faster than using COMPRESS ADVANCED or other compression methods, partly because COMPRESS ADVANCED must scan the table for partially filled blocks and fill those existing blocks before allocating new ones. The INSERTs will happen with direct path writes above the high water mark (HWM), which is always faster than traversing blocks in the buffer cache. As long as you’re not deleting a significant number of rows for each table, the entire table remains compressed with QUERY LOW.
It’s possible I could have chosen a slightly better compression level — but it would be a tradeoff between table size and elapsed time. In this case, the elapsed time was a more important factor. Breaking down elapsed time between I/O and CPU as well as measuring the impact on the cell servers is also a topic for future research.
Conclusion
The effects of a few swiss cheese holes in some of my database tables is not as big a factor on Exadata when offloading full table scans — even less so if storage indexes are in place for the table. And any extra I/O due to partially empty CUs appears to be more than offset by savings in load time and overall segment footprint reduction.
*Addendum
I seem to remember a footnote in an Oracle whitepaper that implies NOAPPEND with an HCC table might re-use existing space if one or more CUs were completely empty due to deleted rows. Something I’ll confirm or deny for a future blog post.
