
I needed to start testing Oracle Exadata storage snapshots to help customers create multiple copies (as snapshot clones) of production for testing, development, and QA without creating multiple full physical copies. Instead of trying to reconfigure the ASM storage in an existing Exadata environment to create the required sparse disk group, I used a new instance of an Exadata Infrastructure (with X8M-2) in Oracle Cloud:
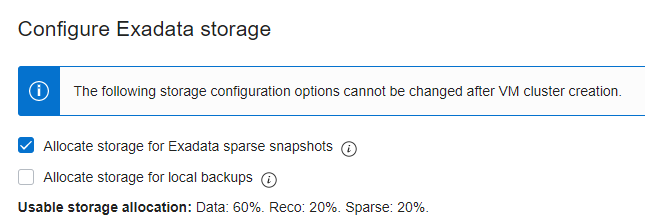
Having a total of 150 TB usable storage space in the X8-M shape would be plenty of space for testing snapshot features at scale. However, looking at V$ASM_DISKGROUP, I was puzzled a bit about how the space in each disk group was reported:

I wasn’t sure how 20% of 150 TB came out to be almost 300 TB; the usable space for DATA and RECO looked fine. I ignored that for the moment, and moved on with creating the test master and clones.
Creating the Test Master and Read-Write Clones
Within the same CDB as the “production” PDB1, I created the test master PDB1_TM and three read-write clones. You can also create the test master in another CDB, or even at a DR site using one of the Data Guard copies, but for this I wanted to keep it simple for the first test. After all the test master and clone provisioning was done, the CDB had essentially four copies of the 500 GB production PDB1:
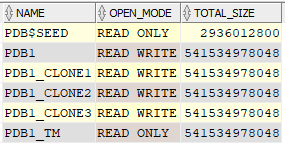
The test master only took a few minutes to create; each of the three clones took a few seconds to create. Clearly, the only initial storage needed was for the source PDB and the read-only test master:

As expected, only about 1 TB of storage in DATAC1 was allocated for full physical copies of PDB1 and PDB1_TM. Each of the three clones uses a small allocation in SPRC1, primarily for metadata.
Leveraging Read-Write Snapshot Clones
Each of the three snapshot clones are independent copies of the production PDB. Since they’re read-write, they can be modified independently of the other clones with no impact on the production PDB. What I did next was add 200 GB of table data to PDB1_CLONE3, and the total size of PDB1_CLONE3 increased by 200 GB as expected:
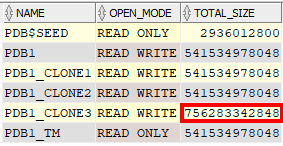
Analyzing Sparse Disk Group Usage
I was once again puzzled by the free space reported in the sparse disk group SPRC1:

For adding 200 GB of table data to PDB1_CLONE3, there was no significant increase in the amount of space used in the DATAC1 disk group, but the amount of space reported in the sparse disk group was reduced by about 724 GB. That seems inaccurate since I only added about 200 GB worth of table data to the PDB, but as I noted at the beginning of this post, the amount of “free” space being reported by the sparse disk group was about 10x higher than I’d expect to begin with.
Conclusions and Next Steps
First, use storage snapshots if you need more than one clone of production for testing, development, or QA! If you use a second Data Guard location, the standby at that location can have redo apply paused to become a test master and refreshed from redo on a regular basis. This not only reduces the amount of time it takes to create a refreshed test master (seconds) but also can deliver a recent image of production to end users on a regular basis without repeatedly creating full copies of production.
As far as how the sparse disk groups are sized and reported, it’s clear that “one size does not fit all”. The assumptions about how big a sparse disk group appears to be can be a problem when you suddenly run out of space by making changes to the snapshot clone. Stay tuned for part 2 of this post where I’ll talk about how grid disks are allocated at the cell level and how you can change the value of VIRTUALSIZE in the CREATE GRIDDISK command for grid disks that will be used in sparse disk groups.
