
Oracle Exadata users have long known that the available compression levels for HCC provide both extreme compression (lower storage footprint) and in many cases improved performance (fewer blocks to read when you know which blocks really need to be read). But the caveat has always been, “But don’t do any DML on HCC tables!”. Performing DELETEs and UPDATEs on HCC tables can have unfortunate side effects, some not so bad and some really bad. If you can use HCC just for “read mostly, write occasionally (APPEND)” data, that’s ideal.
In this post I’m going to focus on UPDATE. It can have the worst side effects on an HCC table, and I’ll show you why, and even provide some tips on what to do when a customer says, “Why can’t I just compress all my tables with HCC ARCHIVE HIGH and not have to buy the Advanced Compression Option?”
Scenario and Setup
In your hypothetical IT department, you want to take a snapshot of DBA_TABLES and DBA_TAB_COLS before a major upgrade for historical purposes. To save disk space on your Exadata storage, you create them with the COLUMN STORE COMPRESS FOR QUERY HIGH clause. Comparing them to their counterparts compressed with Advanced Compression, you see the disk space savings immediately:
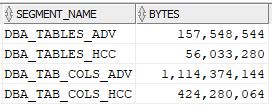
Not bad, HCC is another 2/3rds smaller even compared to using Advanced Compression. Let’s run some simple join queries on the HCC version of these tables:
select /*+ monitor parallel(8) */ owner,table_name,count(column_name)
from dba_tables_hcc
join dba_tab_cols_hcc
using(owner,table_name)
where owner in ('SYS','APEX_040200')
group by owner,table_name
order by 1,2 desc;
We get all the great performance features that we expect from Exadata, such as bloom filters at the storage level and minimizing the amount of data that needs to be returned to the compute layer:



So Much for “READ ONLY”
But look what happens when I need to UPDATE a small percentage of the rows in each table:
update /*+ enable_parallel_dml parallel(8) */ dba_tables_hcc
set last_analyzed = last_analyzed + (1/24)
where owner in ('SYS','APEX_040200');
update /*+ enable_parallel_dml parallel(8) */ dba_tab_cols_hcc
set data_length = data_length + 1
where owner in ('SYS','APEX_040200');
The size of DBA_TAB_COLS_HCC has increased by 50%! The updated rows for SYS and APEX_040200 are no longer compressed with HCC and reside in new blocks that are either not compressed at all or compressed with Advanced Compression.

From a performance perspective, there is also more I/O and much of that sent to the compute layer; offload efficiency has decreased from 87% to 84%:

Even worse, if an UPDATE causes a row to no longer fit into a single block, and you get a lot of chained rows, the storage servers are going to send all of the blocks to the compute layer and your overall throughput and performance will suffer even more:

Yes, that’s not 99%, but 0.99% !!!
In a subsequent blog post I’ll talk more about the pitfalls of row migration, row chaining, and what you can do to avoid those situations.
Conclusions
Using HCC on Exadata is still an effective tool for saving disk space and improving performance even with some DELETE and INSERT /*+ APPEND */ activity*. However, with significant UPDATE activity, you take the risk of using even more storage than if you had just compressed the table with Advanced Compression.
If you want to use HCC and must perform some DML on the table, there are a few guidelines to get “the best of both worlds”. First, avoid UPDATE and MERGE. If you must do DELETEs, reorganize the table with ALTER TABLE . . . MOVE to reclaim disk space left behind from the DELETEs. When you do INSERTs, be sure to use the APPEND hint, Even better, if your table is partitioned, create the partitions with all of the DML activity on the most recent partition with Advanced Compression and rebuild just that partition with some level of HCC when there will not be any future DML activity.
* Side note, bulk INSERTs (array inserts) into HCC tables will use HCC even without direct path operations (APPEND) in 12.2.0.1 and later:
Oracle Support Document 2469912.1 (Inserts on HCC Compressed Tables Can Be Significantly Slower in 12.2 Compared to 11.2) can be found at: https://support.oracle.com/epmos/faces/DocumentDisplay?id=2469912.1
