
Sometimes performance on Exadata can be so good that you don’t think there’s a problem! I recently ran into a situation where an Exadata offloaded full table scan worked great almost all the time, but on occasion the buffer cache commit cleanout on another instance wasn’t done yet — and perhaps on many other instances in the cluster. To solve this issue, I’ll still have to figure out either a more optimal buffer cache size, look at the UNDO tablespace configuration, or partition the table. For now, though, I used some detective work to figure out that I didn’t have to do full table scans after all.
Scenario
A typical query using this 5 TB table would usually have an execution plan with TABLE ACCESS STORAGE ACCESS FULL:

The I/O throughput at the storage level is as good as it gets:

That scan takes only a few minutes, probably due to a combination of storage indexes and columnar format in flash. Still, 5.2 TB once or twice a day adds up. Is that actually necessary for this query? All the required indexes were in place for queries that retrieved a smaller number of rows. And all the statistics and histograms are up to date.
Recently, an analyst noted that a typical row count retrieved was in the range of 50K to 100K, which led me to a re-evaluation of the environment. One of the indexes was hidden:

Which in this case, should not be a problem, because at the database level,

However, the user that was running the query had this statement in their logon trigger:

The solution was imminent. I didn’t want to change the system-level parameter, the visibility of the index, or the logon trigger because there could be many other side effects. For the easy short-term solution I added a hint to the SELECT statement:
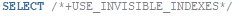
As a result, I now see single block index reads or index range scans — which might not always be optimal for Exadata:

But in this case, I was only returning a very small percentage of the rows in the table. The query now almost always runs in seconds instead of minutes!
Conclusions
Just because Exadata is really fast from an I/O perspective doesn’t mean you can get away with scanning terabytes of data when you only need a small percentage of that data. As the old saying goes, the fastest I/O is the I/O that you don’t have to do. And be sure to know your entire environment when tuning a query: the sizes of the objects involved, the attributes of those objects, the system parameter settings, and any alterations to the runtime environment that may have been changed by a logon trigger.
