
(Updated 6/4/2020 to reflect incremental features in 20c release; updated 11/16/2022 for 21c incremental features; updated 6/15/2024 for 23ai incremental features).
“Bigger on the inside? No. Basic miniaturisation sustained by a compression field. Watch what you eat, it’ll get you every time.” – Doctor Who, not talking about the TARDIS, but instead the Hotel Adlon Restaurant in Berlin
Oracle table compression options are plentiful in Oracle Database 12c, 18c, 19c, 20c, 21c and 23ai in 2024, but can be confusing if you’ve been monitoring the evolution of the syntax you need to manage compression in your tables and indexes. Much of this is due to newer Oracle technologies highlighted and exploited on the Oracle Exadata platform: Hybrid Columnar Compression (HCC) and Oracle In-Memory on any Oracle platform. Another way index compression is leveraged is via ILM policies first introduced in 21c.
Even back in Oracle Database 9i and 10g there was support for basic compression. It was able to compress rows in a block quite well, but the blocks had to be loaded with direct path operations (INSERT with the APPEND hint) or SQL*Loader with the DIRECT=TRUE option. If you didn’t change the data in a compressed table, it performed well, but once you ran any DML (Data Manipulation Language) statements on the rows in a block, you would at best give up the compression for that row and at worst force Oracle to allocate another block for the table to hold the remaining compressed rows and the new or changed row.
Starting in Oracle Database 11g Release 1 (11gR1) you could start using Advanced Compression, which for a slight additional licensing cost you could not only bulk load compressed rows in a table but also add or modify rows in a table while maintaining compression on all rows in a given block with minimal CPU overhead.
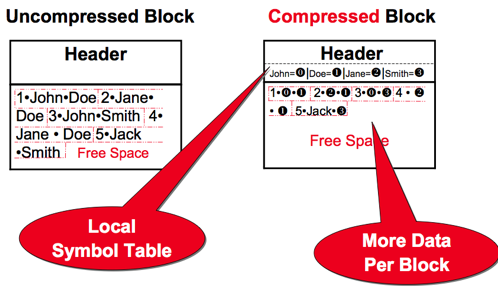
For tables that will have any frequent DML (INSERTs, UPDATEs, and DELETEs) run on them, use Advanced Compression across the board (Exadata and non-Exadata alike). The CPU overhead is minimal and for many applications you might get a 50% compression ratio, or more. Even with Exadata that makes sense because if you must send the entire block (non-smart scans) either to the database servers or during I/O operations at the Exadata storage layer you’re going to send half as many blocks around. To explain Advanced Compression in a nutshell here is how Oracle will compress a block by tokenizing duplicate column values in a block:
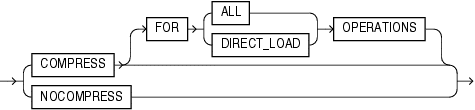
The following syntax diagrams are documentation excerpts from the last few versions of Oracle Database: https://docs.oracle.com/en/database/
In each version, you can see the evolution of the compression-related keywords required by the addition of HCC in Exadata in 11g Release 2 (11.2.0.3/4) and the In-Memory option in Oracle Database 12c Release 1 (12.1.0.2). Let’s start with the relatively ancient Oracle Database 11g Release 1:
11gR1 (11.1.0.7)
Row store compression only!
11gR2 (11.2.0.3/4)
Compression could be HCC, but it’s not obvious yet that the compression was “column store” on Exadata:
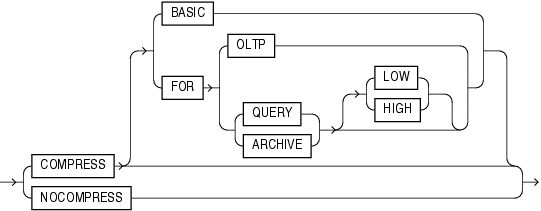
12cR1 (12.1.0.1)
HCC compression is now more obvious by differentiating between “row store” and “column store”, but no “row level locking” or “in-memory” option yet:
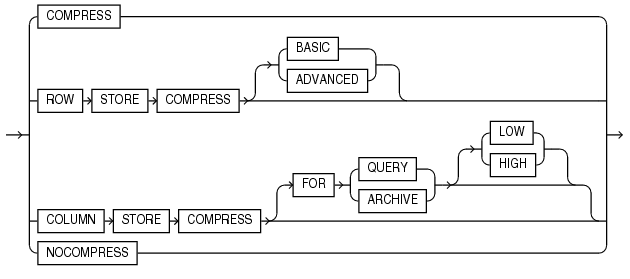
12cR1 (12.1.0.2)
Aha, now we can also have columns of a table or the entire table “in-memory”! And the compression algorithms look suspiciously like those found in Exadata HCC storage:


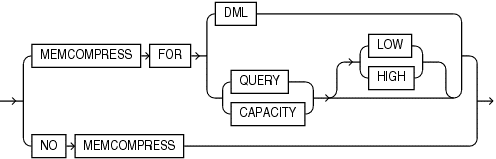
12cR2 (12.2.0.1)
Not much new in 12c Release 2. Same high level syntax, but with additional in-memory functionality for Integrated Lifecycle Management (ILM) and more options for distributing in-memory information across RAC node instances:

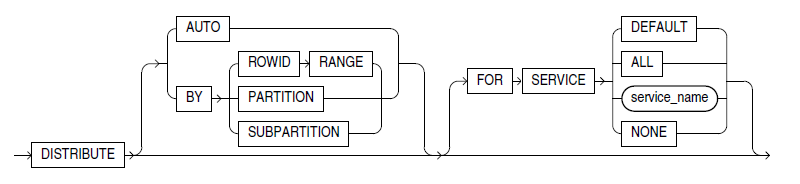
18c and 19c
From a syntax perspective, the compression clauses haven’t changed much with 18c and 19c – not surprising, given that Oracle Database version 18c is more or less version 12.2.0.2 and 19c is more or less version 12.2.0.3. However, one key feature added in version 18c cuts across Oracle’s big data support (e.g. external tables), in-memory, and compression by enabling in-memory support for external tables (how cool is that?):

20c
20c and 21c are interim releases, and the compression-related enhancements are detailed in the documentation. Much like with 18c and 19c, the compression-related syntax has stabilized, but with Oracle’s new release cycle paradigm, releases 20c and 21c will have more new features in addition to the routine bug fixes before the next LTS release (23c).
The syntax for the “in-memory compression” clause has been enhanced:
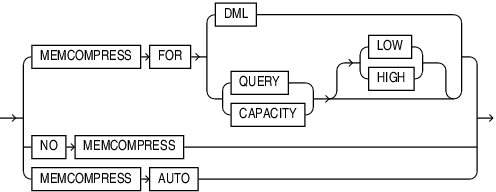
What is “MEMCOMPRESS AUTO“? Well, it does lend itself to the emphasis on autonomous databases. The documentation only says “Specify MEMCOMPRESS AUTO to instruct the database to manage the segment including actions like evict, recompress, and populate.” While the parameter INMEMORY_AUTOMATIC_LEVEL can have a value of HIGH starting in 19c, when it’s set to HIGH in 20c, it can automatically evict cold segments or recompress “cool” columns.
21c
There are no significant changes to table compression or index compression, but the relatively new index compression levels in 12.1.0.2 and 12.2.0.1 (COMPRESS ADVANCED LOW and COMPRESS ADVANCED HIGH) can be leveraged with ADO policies by adding the ILM attributes to the CREATE INDEX or ALTER INDEX statements:
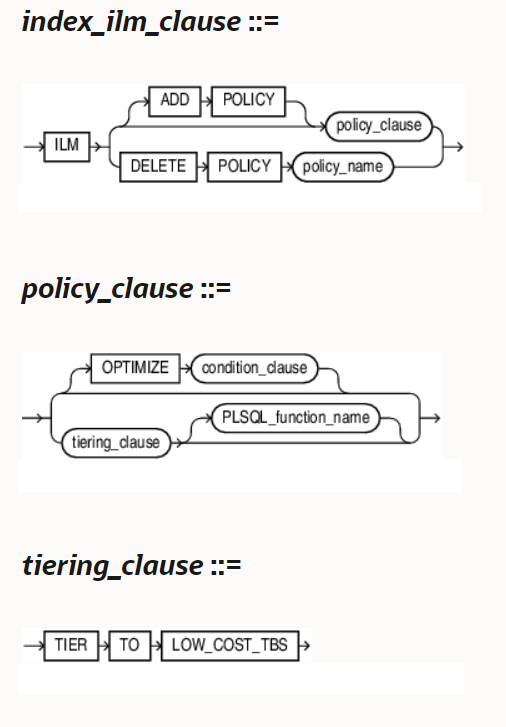
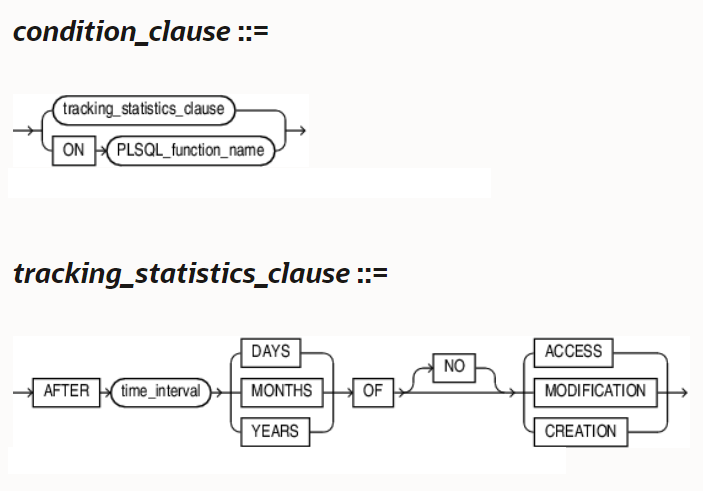
Not only can you use these policies to automatically compress, shrink, or rebuild indexes but also move those indexes to a different (usually cheaper) storage tier.
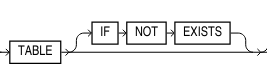
23ai
The syntax for CREATE TABLE and its compression clauses, specifically for Exadata, remains essentially the same. A few more usability features have appeared, and long overdue, such as avoiding the attempt to create a table if it already exists and as a result avoiding an error message:
And options like specifying ALL for the In-Memory column specification instead of a very long list of included or not included columns and a smaller exclusion list:
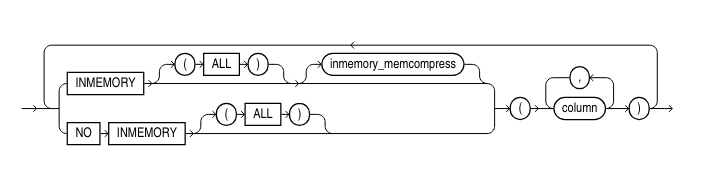
Otherwise, it seems like there is not much new in the Exadata storage cell compression methodologies. Well, except for how in-memory columns are compressed even further on X10M storage servers. This will be a topic for a future blog post!
And of course the new 23ai vector datatype that should offload to Exadata storage cells just like most other Oracle datatypes. I suspect they will — and another great topic for a future blog post measuring how much improvement we’ll get by leveraging Exadata storage cells for performance under 23ai.
Conclusions
Even though it doesn’t seem like it, there remain only six different compression methods available to you: BASIC compression, Advanced Compression, and four levels of HCC (Exadata and ZFS storage only). It would be seven if you count no compression (NOCOMPRESS) as a compression level. But really it’s back to six because basic and advanced compression give you roughly the same compression ratio with advanced compression letting you do more with the rows without losing the compression.
Why it seems like there are more than that (beyond the changing and overlapping keyword options as you move from version to version) is because these compression technologies are available at so many levels: the table level, storage level, for indexes (beyond basic index compression from previous releases), column stores in memory, and even at the network level.
Regardless of how much disk space you have or how fast your network is, if you have a few CPU cycles available on a regular basis, compressing your data using one of these methods makes sense. Oracle provides a variety of table and index compression options to match almost every combination of hardware, software, and application. Compress away!
